For many years, mankind had the utopian goal of building intelligent machines that could think and behave like people. One of the most intriguing concepts was to enable computers to “see” and comprehend their surroundings.
Computer vision technology has made great strides toward inclusion in our daily lives as a result of developments in artificial intelligence and processing capacity. The branch of artificial intelligence, computer vision, focuses on developing and utilizing digital systems to process, examine, and interpret visual input.
A neural network anticipates items in a picture and identifies them using bounding boxes in object detection, a sophisticated type of image classification. Thus, the term “object detection” refers to the identification and location of items in an image that fall under one of several established classifications.
One such object detection algorithm is YOLO. In this article, we will talk about YOLO, the structure of YOLOv3, its relevance, and associated concerns.
What is YOLO?
The “You Only Look Once,” or YOLO, a family of CNN, is noteworthy because it produces results that are almost on par with state-of-the-art technology using a single end-to-end model that can identify objects in real time.
This program searches for and identifies various objects in a picture (in real-time). The class probabilities of the found photographs are given, and object detection in YOLO is carried out as a regression task.
A Convolutional Neural Network (CNN) is utilized by YOLO to recognize objects in real-time. As the name suggests, the method only needs one forward propagation through a neural network to detect objects.
Object detection designs having only one stage are called single-stage object detectors. They view the detection of objects as a straightforward regression issue. This suggests that a single algorithm run is used to do prediction throughout the whole picture.
Multiple class probabilities and bounding boxes are forecasted simultaneously using CNN. In simple words, the network outputs the class probabilities and bounding box coordinates straight from the input picture.
These models exclude the region proposal stage, or Region Proposal Network, which is often a component of Two-Stage Item Detectors, which are regions of the picture that could contain an object.
The YOLO algorithm comes in different variants. The most popular versions are YOLO v1, v3, v4, and v5. In 2022, YOLOv6 and YOLOv7 were released within close days.
What is YOLOv3?
A real-time object identification algorithm called YOLOv3 recognizes objects in films, live feeds, or still photos. The YOLO machine learning technique uses a deep CNN’s characteristics to identify objects.
Version 1 of YOLO was developed in 2015, while version 3 was developed in 2018. The YOLOv3 feature detector’s architecture was influenced by well-known architectures like ResNet and FPN (Feature Pyramid Network).
To process images at a different spatial compression, Darknet-53, the YOLOv3 feature detector’s codename, has 52 convolutions with skip connections similar to ResNet and a total of 3 prediction heads similar to FPN.
Initially, the YOLOv3 algorithm divides a picture into a grid. Each grid cell foretells the presence of a specific number of bounding boxes (also known as anchor boxes) around items that perform well in the aforementioned predetermined classifications.
Only one item is detected by each bounding box, which has a corresponding confidence score indicating how correct it expects that prediction to be. The ground truth boxes’ dimensions from the original dataset are clustered to identify the most typical sizes and shapes before being used to create the border boxes.
Like YOLOv2, YOLOv3 performs well across a variety of input resolutions. When compared to its rival Faster-RCNN-ResNet50, a faster-RCNN architecture that employs ResNet-50 as its backbone, YOLOv3 obtained an mAP (mean average accuracy) of 37 when tested with input photos measuring 608 x 608 in the COCO-2017 validation set.
Other designs, such as Mobilenet-SSD, earned an mAP of 30. However, they took YOLOv3 a similar amount of time to recognize the pictures.
Significance of YOLOv3
In terms of speed, accuracy, and class specificity, YOLOv3 and earlier versions differ significantly. YOLOv2 and YOLOv3 are poles apart in terms of accuracy, speed, and architecture. Two years before YOLO v3, in 2016, YOLO v2 was released.
While YOLOv3 officially utilizes Darknet-53, YOLOv2 was employing Darknet-19 as its backbone feature extractor. We can observe that ResNet101 is 1.5 times quicker than Darknet-52 from a YOLOv3 study. The precision is the same as ResNet-152 but two times quicker, so the accuracy shown does not need any trade-off between accuracy and speed between Darknet backbones.
In terms of mean average precision (mAP) and intersection over union (IOU) values, YOLOv3 is quick and precise. The graph that follows, which was updated and obtained from the YOLOv3 publication, displays the average precision (AP) of identifying tiny, medium, and big pictures using different algorithms and backbones. For that variable, the greater the AP, the more accurate it is.
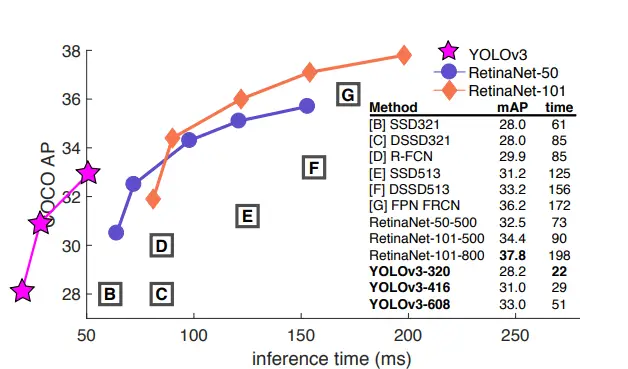
Because of how bad YOLO was at identifying small items, the precision for small objects in YOLOv2 was unmatched by other algorithms. Compared to other algorithms, such as RetinaNet (21.8) or SSD513, which had the second-lowest AP for tiny objects, it performed poorly (AP = 5.0).
Applications of YOLOv3 in Real-life
- Security: YOLO can be employed in security systems to impose security in an area.
- Autonomous vehicle: In driverless vehicles, the YOLO algorithm can be used to find nearby things like other cars, pedestrians, and parking signals. Since no human driver is operating the automobile, object detection is done in autonomous vehicles to prevent accidents.
Eventually, YOLO algorithms will take the role of the traditional face detection systems in our computers and mobile devices. To recognize people, objects, and other objectives in real-time, technologies such as drones or robots that employ machine vision, will start embracing YOLO.
Issues with YOLOv3
Despite being extremely precise, YOLOv3 has a flaw – it is skewed (meaning biased). It cannot accurately recognize the same thing on a smaller scale if it is trained with bigger objects.
The YOLOv3 does show a trade-off in speed and accuracy compared to RetinaNet because RetinaNet’s training time is longer than YOLOv3. The accuracy of YOLOv3 can be made equivalent to the accuracy of RetinaNet only by having a bigger dataset.
A prominent example would be traffic detection models, where a large amount of data may be utilized to train the model due to a large number of photos of different cars. On the other hand, YOLOv3 can not be optimal for utilizing niche models in situations where huge datasets are difficult to gather.
When compared to Faster R CNN, it has a lower recall and a higher localization error. Since each grid can only suggest two bounding boxes, YOLOv3 struggles to recognize nearby items. Furthermore, it has difficulty detecting tiny things.
Final Thoughts
YOLO revolutionized object detection-related computer vision research being an extremely quick and precise object recognition technique.
Novel feature extraction, known as Darknet-53, as well as a large portion of the YOLOv3 architecture in general, have undergone significant changes in versions YOLOv4 and YOLOv5. The community of computer vision experts has also expressed disapproval of Ultralytics’ adoption of the model name YOLOv5.
However, YOLOv4 has been accepted by the public as a legitimate advancement over YOLOv3, and the moniker is not as divisive. On the other hand, YOLOv5 has unvalidated evidence to support its advancement above YOLOv4.
Related Articles
Recent Posts
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules. In this tutorial, let's understand what modular...
While Flask provides the essentials to get a web application up and running, it doesn't force anything upon the developer. This means that many features aren't included in the core framework....
