Welcome to a tutorial on web scraping using Python and Selenium. In this post, we are going to be coding a web scraping program to search and download images from Google.
Before getting into action, there are some simple questions that you might be curious about web scraping. If you already have an idea about these, feel free to skip to the tutorial.
What Is Web Scraping?
Web Scraping is the process of extracting information available on a website using automation software. We use certain drivers and software to access a website and its components to download or scrape data for processing.

Any program involving web scraping has some basic, common methods. First, the program uses a browser driver to open the desired website through a URL, and once the page is open, the data extraction is done by the Selenium tools that are available under the Python Selenium library.
These data are in turn used for data analysis, or if connected to a database, then the data might be stored there. The uses of this data are numerous and are only limited by your creativity.
Web scraping is not only done for data extraction, but we can also use this as automated testing software.
Is Web Scraping Legal?
Not all websites allow web scraping. So before you get started on the program, you need to check the policies of the website. Some websites use captchas and hidden objects to prevent automation tools from scraping their data.
It is not illegal, but one should maintain ethical constraints while doing web scraping. A lot of startups use web scraping over the use of APIs because of the need for partnerships to access information through APIs.
What Are the Uses of Web Scraping?
Companies use the scraped data for various purposes. Some of the noteworthy ones are:
| Web Scraping Use Case | Description |
|---|---|
| Sentiment Analysis | If a company wants to know what consumers feel about their product, they can simply scrape the reviews of their company posted on various social media websites and perform sentiment analysis on them. |
| Market Research | If a company wants to release a new product, they need to have an idea about the kind of products that consumers are buying. By scraping data related to the trend of buying products, they perform market analysis research to modify their business strategies to better suit the consumer needs. |
| Data Monitoring | By designing an automation tool to scrape continuously changing data, companies can monitor the parameters associated with it. For example, if a company wants to know the average temperature recorded for every week, they can simply design a web scraping program to record the weather data every day and can compute the average at the end of each week. |
| Price Monitoring | Constantly changing prices can be monitored, and the pattern and trends can be analyzed easily with the help of web scraping. Examples: Stock market analysis, Cryptocurrency analysis, etc. |
Selenium
Selenium is a Python library that enables us to work with browser drivers and scrape off data from websites. Data can be extracted directly as selenium objects, and their parameters can be accessed through inbuilt selenium functions.
Some of the noteworthy features of Selenium are:
- It is open-source
- It is free
- Selenium is easy to understand
- Selenium is highly tester-friendly
- Selenium is also Dynamic (This means it can work on pages that load new content on clicks without moving to another URL)
Web Scraping Tutorial: Downloading Images Automatically From Google
Step 1
Install Selenium and import it into your code. To install selenium, you can run the following command in your terminal or command prompt.
pip install seleniumOnce your run this command, Python will automatically install selenium on your system.
Now, install the webdriver_manager module by running the following command in your terminal.
pip install webdriver_managerNow, open your code editor and start writing code.
Add the following code to your program at the beginning:
from selenium import webdriver
import time
import urllib
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
The last line of code will install the Chrome Driver on your system.
Step 2
Get the URL that you are going to be web scraping on. Pass the URL as an argument to the function driver.get().
search_url="https://www.google.com/search?q={s}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
driver.get(search_url.format(s='Super Heroes'))
In the search_url variable, the URL is stored as a string. It is a generic URL for a google image search. Now we can format it into our desired search by adding the search word in the place of ‘s’. In this example, we have formatted the value of s to be ‘Super Heroes’.
Step 3
Now we navigate through the webpage opened by the driver by scrolling down to the end. We can also add a small interval of time for the document to render the images so we wouldn’t be accessing half-loaded objects.
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(5)The execute_script function will scroll down the document (body of the web page), and we give it 5 seconds for the images to load. The value of the time interval is totally up to you. Just make sure you provide adequate time for image rendering.
Step 4
Now let’s see how we can identify the images. We need to find an attribute that is unique only to images and not another type of object so that we can separately access the images alone.
We can now go to the URL and explore the “inspect” option of the page to understand the attributes of each object. To access this option, go to the page and press “Ctrl + Shift + I” (or you can right-click the mouse and select Inspect option).
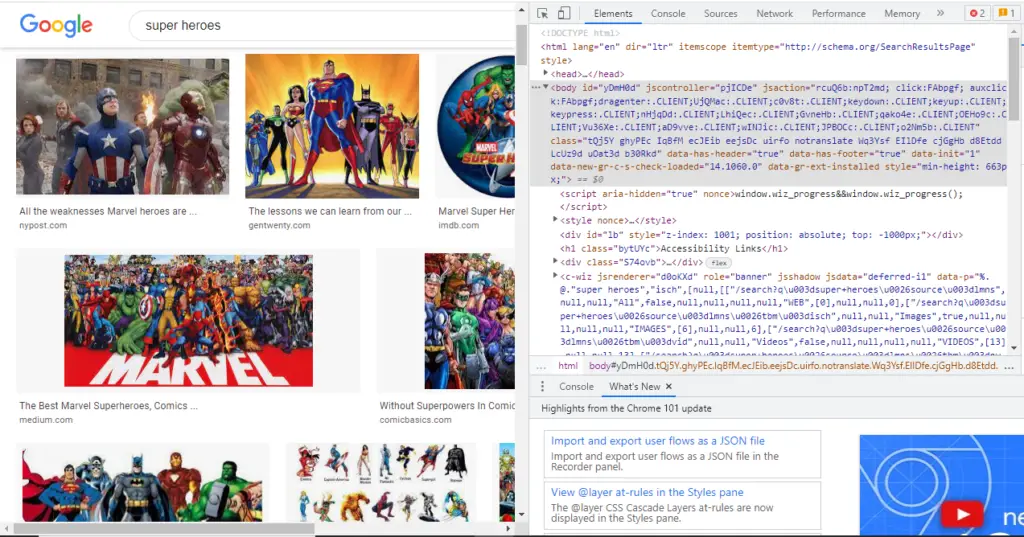
Click on the top left icon on the newly opened window, and then click on an image to highlight all the attributes associated with it.
We can observe that there is an attribute named “Class“. You can use the tool on the top left to view the attributes of various objects and observe the pattern in Classes.
The images have a Class name of the pattern (“… Q4LuWd”). So we will extract the objects that have a class name containing the “Q4LuWD” pattern.
We can use the find_elements_by_xpath() function to identify images.
imgResults = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")All the images containing the “Q4LuWd” in the class name are now stored in imgResults as Selenium objects. Now, if you print them, you will get only the description of the selenium object. To retrieve an image, we need to access its “src” attribute.
Step 5
Now let’s download the images. The value of the src attribute is a URL that will open the image on a new page where we can use python functions to download the image.
To access the src attribute simply use Selenium_image_object.get_attribute(‘src’). The get_attribute function returns the attribute value of the parameter sent as an argument.
src = []
for img in imgResults:
src.append(img.get_attribute('src'))The list of image URLs is now stored in a list of strings called src. We now have to iterate through the list and use a python function to download the image.
for i in range(50):
urllib.request.urlretrieve(str(src[i]),"superhero{}.jpg".format(i))
This loop will run 50 times and download 50 images to your project folder.
The “urllib.request.urlretreive()” takes two arguments. The first is a URL, and the second is a file path where you want to store the downloaded entity.
Here we give our image the ‘src’ attribute as URL, and the file path is your choice as to where you want the image to download. Make sure the file extension is added at the end (“.png” or “.jpeg” or “.jpg” for image files).
Step 6
The web scraping program is ready for execution. Here is the complete code:
from selenium import webdriver
import time
import urllib
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
search_url="https://www.google.com/search?q={s}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
driver.get(search_url.format(s='Super Heroes'))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(5)
imgResults = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
src = []
for img in imgResults:
src.append(img.get_attribute('src'))
for i in range(50):
urllib.request.urlretrieve(str(src[i]),"superhero{}.jpg".format(i))Now you can run this Python program. Go to the file path given as the argument (project folder) and you can see your downloaded images.
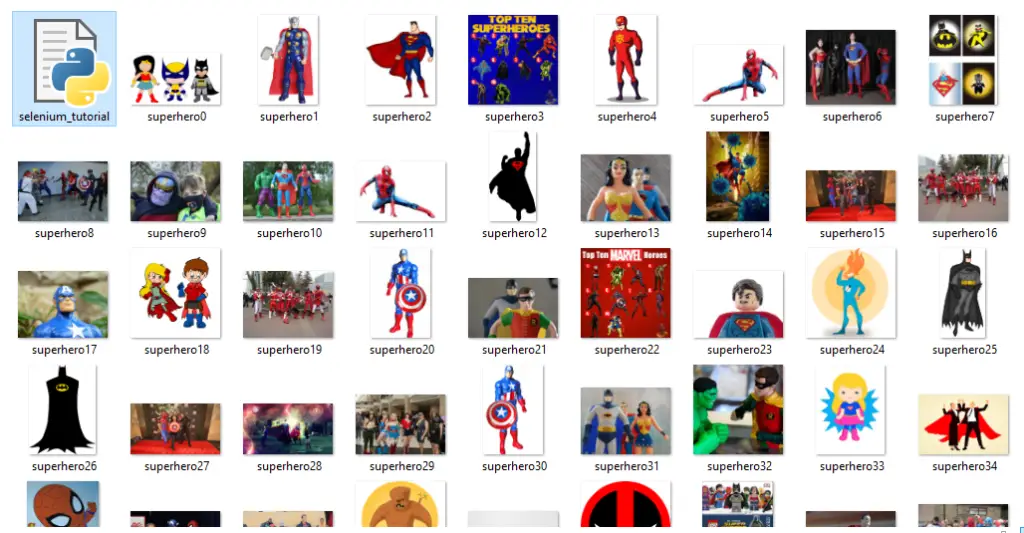
Final Thoughts
We have successfully scraped images from google and have downloaded them to our local disk. You can experiment with this very code by changing the search word, or you can even change the attribute that you are choosing to select the images. This way, you can get more fluent with your web scraping techniques.
Try adding the acquired images or any kind of data to a database. Now that you know how to extract information from the Internet, you can combine your program with other programs that process this information and yield useful observations.
For example, if you want to create an image classification model in machine learning, you can use web scraping to download images from the Internet and create your own dataset. This way, you can put your web scraping skills into real-time applications.
Related articles:
- Web Scraping Using Python BeautifulSoup
- Web Automation With Python Selenium (Automate Facebook Login)
I hope this tutorial was of the best help to you. All the very best for your future coding endeavors. Happy coding!
Recent Posts
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules. In this tutorial, let's understand what modular...
While Flask provides the essentials to get a web application up and running, it doesn't force anything upon the developer. This means that many features aren't included in the core framework....
