In this article, you’ll learn the basics of the Pandas library in Python. Pandas is a very important Python library for those who are interested in machine learning and data science.
Let’s dive right in and learn to use this library.
What is Pandas?
Pandas is a Python library that is used for faster data analysis, data cleaning, and data pre-processing. Pandas is built on top of the numerical library of Python, called numpy.
Before you install pandas, make sure you have numpy installed in your system. If numpy is not much familiar to you, then you need to have a look at this article. Brush up your numpy skills and then learn pandas.
You might have heard about data-frames, which is a common term in machine learning. This word comes from pandas. Pandas library helps us to make data-frames easily. Later in this tutorial, we will talk about data frames in detail.
Pandas library is often compared to excel sheets. A lot of features in excel sheets are available in the pandas as well.
Installing Pandas
Now let’s see how we can install pandas.
If you have numpy installed in your system, let’s install pandas.
Just like you did with numpy, you can install pandas using any of the following methods.
- If you have anaconda, you may already have pandas in your base environment. Else, try installing it using the help of the Anaconda Navigator GUI.
- If you have anaconda or miniconda, type in the following command in your command prompt or anaconda prompt:
conda install pandas- If you don’t have condas, you can type in pip install pandas (for Windows) or pip3 install pandas (for Mac) in your command prompt or terminal.
Now we have the pandas library ready. Let’s see how we can import it into our code.
Importing Pandas
We can import pandas into our code using the import keyword. Also, don’t forget to import numpy before we import pandas. This is always a good practice.
import numpy as np
import pandas as pdIt is a common practice among programmers to use pandas as pd. What it means is, from now on, we can use pd instead of using pandas in our code.
You can code in your favorite editor. I use the jupyter notebook and highly recommend that to you as well.
Series in Pandas
Pandas library has something called series. A series is a one-dimensional labeled array capable of holding any data type in it. A series has data and indexes.
The difference between a series and a normal list is that the indices are 0,1,2, etc., in lists. But in series, we can define our own indices and name them as we like.
Let me give you an example.
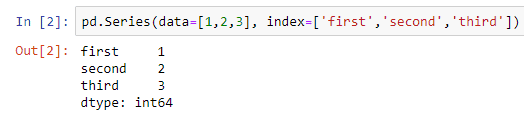
We can create a series using the Series() method. Note that we have mainly two arguments for this method, which are data and index.
I hope you understand the series in pandas.
Now, let’s see how we can convert a dictionary into a series.
Let’s say we have a dictionary called phonebook. We can convert this into a series by passing this dictionary directly as the parameter.
Let’s see the code for that.
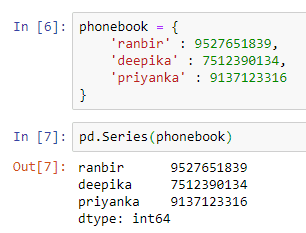
Notice that the dictionary is automatically converted into a series.
Accessing Elements in a Series
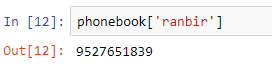
If you want to access an element from a series, you can use the index of the data you need inside square brackets, along with the name of the series.
For example:
Adding two Series
We can add two series together using the + operator. But the data inside the series gets added only if the name of the indices of both the series is the same.
Feeling confused? See this example:
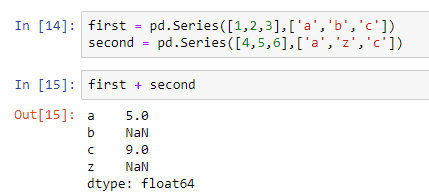
You can see that only the data at a and c are added since both series have the same indices. At b and z, it shows NaN.
Also, note that all the values are automatically converted into the float type so that you don’t lose precision.
Data Frames in Pandas
We have one more important data structure in pandas, which is the data frame. A Data frame is a two-dimensional data structure containing rows and columns that can hold any type of data.
You can think of it as a spreadsheet or an excel sheet. Data frames are very similar to them.
Let’s see how we can create a data frame.
For this example, we are using the randn method of numpy to first create a 2-dimensional matrix with random values. Then, we will convert this matrix into a data frame using the method pd.DataFrame().
We need to pass the matrix, name of the rows, and name of the columns as the parameters of this method.
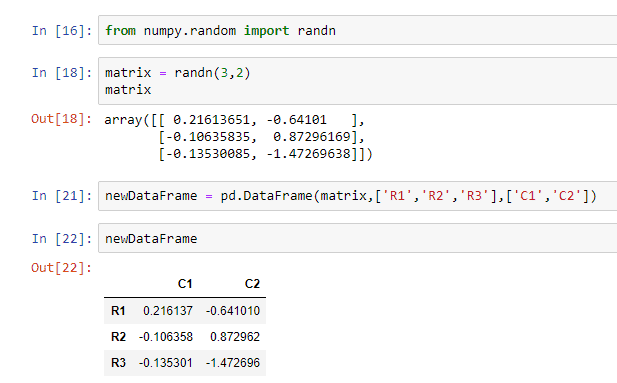
You can see that our data frame looks like a spreadsheet or excel sheet.
Accessing Columns in Data Frame
You can select the elements from a data frame by specifying the name of the column that you want to select within square brackets, along with the data frame name.
For example, if we want to select the first column only, then we need to specify C1 within the square brackets.
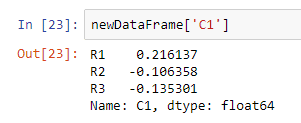
If you want more than one value, you can pass in a list inside the square brackets.
Adding a New Column
Let’s see how we can add a new column to this data frame. Let’s say we need column C3, which is the sum of the elements in C1 and C2.
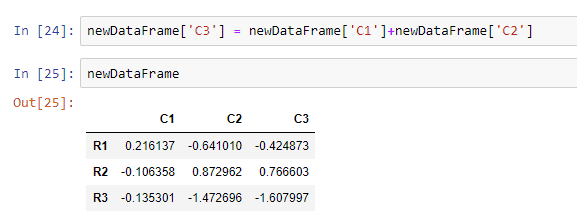
Thus, we got a new column to our data frame.
Deleting a New Column
You can delete any column or row using the drop method. Let’s say we want to delete column C2.
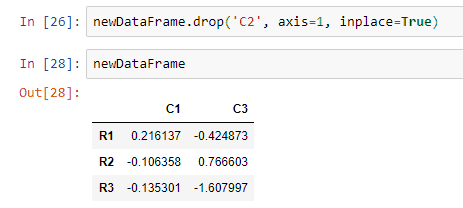
Here, axis=1 means we are deleting a column. If you want to delete a row, then you can use axis=0.
Also, inplace=True means you are actually deleting your column from the data frame.
Accessing Rows in Data Frames
You can select a particular row from a data frame using two methods, either loc or iloc.
In the loc method, you need to pass the name of the row inside square brackets.
We can also use iloc. But here, instead of the row name, we pass the number of the row.
Take a look at this example:
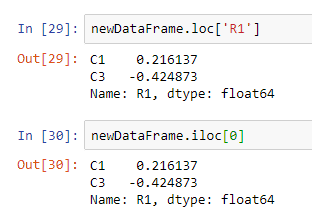
You can see that by doing any of these methods, we get the same result.
Selecting a SubMatrix
We can select a submatrix by using the loc method. We need to pass the rows and columns we need, inside a list.
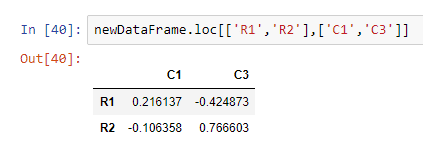
Conditional Selection
Conditional selection in pandas is similar to that of numpy. We can select the data based on certain conditions.
Let’s see some examples.
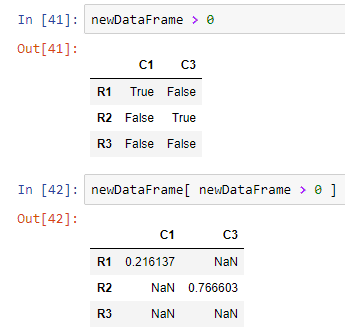
Setting New Index to the Data Frame
If we need to change the name of the indices, that is, the rows and columns of the data frame, then we can do it very easily in pandas with the set_index() method.
Let’s see an example.
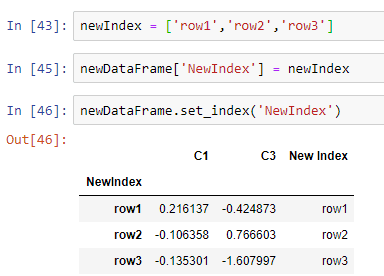
You can do the same with columns as well. Don’t forget to add axis=1 while dealing with columns.
Data Clean-Up using Pandas
While doing machine learning problems, most of the time, the available data may not be clean and perfect. There may be missing values, unwanted data, and a lot of problems.
So, it is very important to clean the data before we use it for machine learning purposes. Let’s see some ways by which we can clean the data in pandas.
Let’s look at this example. Note that some values are marked NaN, which means null values.
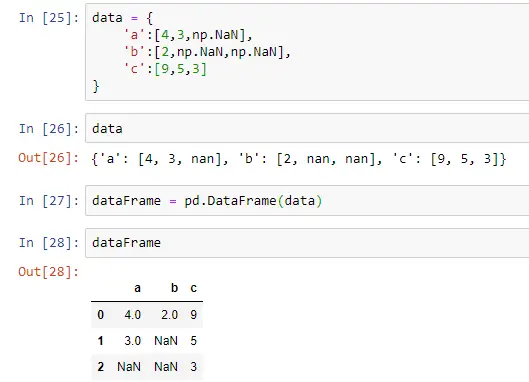
Now, we will see how we can clean up this data.
Dropping Null Value Rows
If you want to avoid all the rows that contain some null values, then you can use the dropna() method for that.
Take a look at this example.
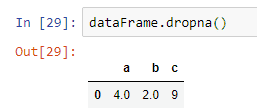
This method is very rarely used since no one wants to lose their valuable data in the non-null cells of these rows.
So, let’s look for a better method to avoid these null values.
Filling Null Values by Some Other Values
Let’s see how we can fill these null value cells by some other values. We can use the fillna() method for that.
For example, if we want to fill the null values by replacing them with the word hai, we can pass ‘hai’ as the parameter of the fillna() method.
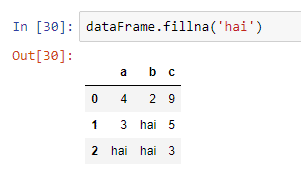
You can see that all the null values are now replaced by hai.
Let’s see another strategy. It will be better if we replace the null values with the mean of the available values.
Let’s see an example in which we fill the null values, with the mean of the other values of the first column (column a).
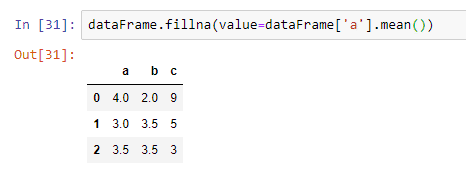
Now, you can see that all the null values are replaced by 3.5.
Grouping of Data
To show you how to group data, I’m just randomly adding some names to the rows. I’m naming two rows the same name and showing you how to group those data. For grouping, we use the groupby() method.
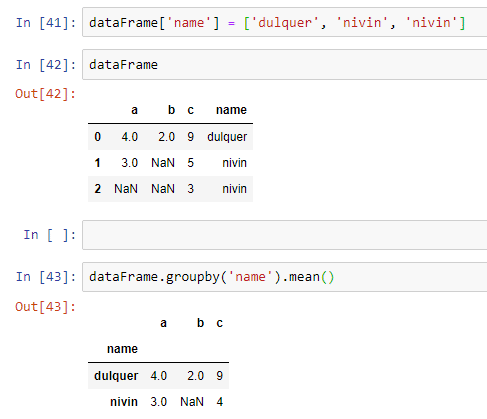
Here, I grouped the rows using their names and found the mean. Instead of mean, you can use sum() to find the sum, std() to find the standard deviation, etc.
Reading CSV Files
If we have some data in our CSV file and we want to read that, then we can use the read_csv() method to read the data in pandas. You just need to pass the file name or path as the parameter of the method.
Let’s see an example.

In this case, our CSV file is in the same folder as that of the python notebook file, where I’m coding. So, make sure that the CSV file is in the present working directory.
In other cases, you will need to pass the complete path of the file as the parameter.
Also, we can read many other types of files such as Excel, HTML, SQL, and many more using pandas. There are similar functions like read_excel(), read_sql(), etc. for this purpose.
Writing to a File
We can also create files from the data frames that we have. For example, if we want to convert our data frame to a CSV file, then we can use the to_csv() method.
Pass the data frame as the first parameter of this method. The second parameter should be index=True.
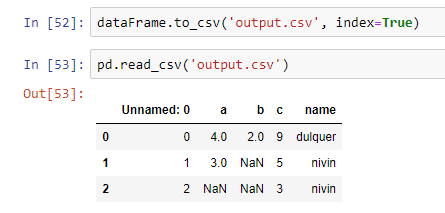
You can see that a new CSV file is created in the same folder, and that file contains all the data that we have in our data frame.
Also, you can write to many other types of files as well.
Conclusion
We’ve learned the basics of pandas, which is a very important python library, used for data analysis, data cleaning, and data pre-processing.
Pandas library provides the ability to read many types of data files and also to write our data frames to these files.
I hope this article was helpful. If you have any doubts or queries regarding this topic, feel free to let me know in the comments.
If this article, I would appreciate it if you would be willing to share it.
Happy coding!
2 thoughts on “A Beginner’s Guide to Pandas Library [with Examples]”
Leave a Reply
Recent Posts
Hyperliquid Founder Insights Funding Sources Path to Growth The initiative behind Hyperliquid – децентрализованная биржа бессрочных контрактов и...
Hyperliquid Web3 Self Custody Applied to Derivatives Trading
Hyperliquid Web3 Derivatives Trading With Self-Custody Principles Connect a non-custodial wallet to trade perpetual swaps with up to 50x leverage–no deposit locks or withdrawal delays. Funds stay...

can we write a coding for json file sending data to mysql database without models and how is it possible to send json file to my sql database in django
Hi, I haven’t done this before, so I can’t give you an accurate answer to this. However, when I looked around the Internet, I found that it is possible. I can point you to one article. Hopefully, it would help.
https://www.laurencegellert.com/2018/09/django-tricks-for-processing-and-storing-json/