A Python module is a Python file that contains a set of in-built functions and variables that can be used in your program. A module can be of two types: in-built or user-defined. The HTML module in Python is an in-built module.
In this article, let’s look at what the HTML module is and the different methods it has to offer, with suitable example code for better understanding and clarity.
Let’s dive right in.
What Is Python HTML Module?
The HTML module in python is exclusively built to support coders who wish to work with HTML. This module defines HTML manipulation utilities.
You do not need to install the Python HTML module on your system because it is built-in. To utilize the Python HTML module, use the import keyword to import the HTML module.
We have a standard and clear HTML code utilized for encoding and decoding within the Python HTML module. [Reference]
The html module in Python contains two functions: escape() and unescape().
html.escape()
Using the html.escape() function, we can turn the HTML script into a string by replacing special characters in the string with ASCII characters.
- Syntax: html.escape(String)
- It returns a string of ASCII characters from HTML.
For example, consider the following HTML code.
<!DOCTYPE html>
<html>
<head>
<title>Python HTML Module</title>
</head>
<body>
<h2 style="text-align:center;">Hi , I am the HTML code</h2>
</body>
</html>Let’s look at how to use the html.escape() function to encode the HTML code.
import html
html_code = '<!DOCTYPE html> <html> <head> <title>Python HTML Module</title></head><body><h2 style="text-align:center;">Hi , I am the HTML code</h2></body></html>'
encoded_code = html.escape(html_code)
print(encoded_code)Output:

The escape() function in the Python html module is used to encode HTML code. It changes the special characters (<, >,&, etc.) to HTML-safe sequences.
If the optional flag quote is set to true (the default), the quotation mark characters, as well as double quote (“) And single quote (‘), are additionally translated.
You can also manually change the quote flag to False.
import html
html_code = '<&!DOCTYPE html> <html> <head> <title>Python HTML Module</title></head><body><h2 style="text-align:center;">Hi , I am the HTML code</h2></body></html>'
encoded_code = html.escape(html_code,quote=False)
print(encoded_code)Output:

html.unescape()
In simple terms, by using the html.unescape() function, we can turn an ASCII string into an HTML script by substituting the ASCII characters with special characters.
- Syntax: html.unescape(String)
- It returns an HTML script.
The html.unescape() function accepts only one parameter, an encoded string. It converts all named and numeric character references in strings to the corresponding Unicode characters.
For example, let’s consider the following encoded HTML code.
<&!DOCTYPE html> <html> <head> <title>Python HTML Module</title></head><body><h2 style="text-align:center;">Hi , I am the HTML code</h2></body></html>Let’s convert this into HTML using the unescape() method.
import html
encoded_code = '<&!DOCTYPE html> <html> <head> <title>Python HTML Module</title></head><body><h2 style="text-align:center;">Hi , I am the HTML code</h2></body></html>'
html_code = html.unescape(encoded_code)
print(html_code)Output:

The unescape() method applies the HTML5 standard guidelines for valid and invalid character references, as well as the list of HTML5 named character references specified in html.entities.html5.
HTML Module in Older Versions of Python
If you are using an older version of python, you may encounter this error when trying to import the HTML module.
Error: Import HTML importerror: No module named HTML
To resolve this error, you have to run the below codes.
- To install the HTML module, run the following code in your terminal or command prompt.
pip install html To import the HTML module in Python, use the following code (for older versions).
from html import HTML
obj = HTML()
obj.p('Hello, world!')
print(obj)Those who have newer versions of Python can skip this.
Submodules in Python HTML Module
Submodules in the HTML package are:
- parser
- entities
html.parser
The HTML parser is a tool for parsing structured markup. It is used to parse HTML files.
These are some of the parser methods available in this submodule.
| Method | Use case |
|---|---|
| HTMLParser.handle_data(data) | This method is used to handle the data contained between HTML tags. |
| HTMLParser.handle_comment(data) | This method is used to handle HTML comments. |
| HTMLParser.handle_starttag(tag, attrs) | This method is used to handle HTML start tags. The opening tag is included within the parameter tag, and the attribute of that tag is contained within the attrs parameter. |
| HTMLParser.handle_endtag(tag, attrs) | This method is used to handle HTML end tags. The closing tag is contained within the parameter tag, and the attribute of that tag is contained within the attrs parameter. |
| HTMLParser.feed(data) | This method can be used to supply data to the HTML parser. |
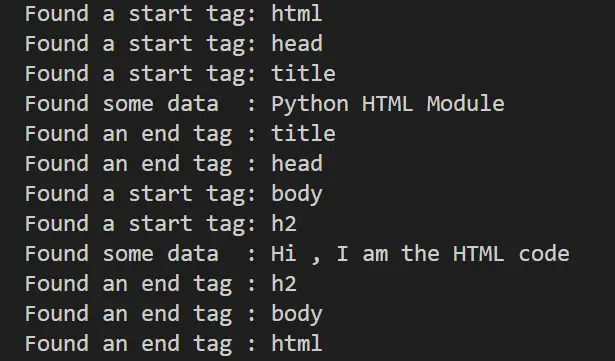
Here is an example of an HTML parser application:
from html.parser import HTMLParser
class MyParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Found a start tag:", tag)
def handle_endtag(self, tag):
print("Found an end tag :", tag)
def handle_data(self, data):
print("Found some data :", data)
parserObject = MyParser()
parserObject.feed('<!DOCTYPE html><html><head><title>Python HTML Module</title></head><body><h2 style="text-align:center;">Hi , I am the HTML code</h2></body></html>')
Output:
html.entities
The html.entities submodule includes HTML generic entity definitions. There are 4 dictionaries defined in this module, which are html5, name2codepoint, codepoint2name, and entitydefs.
| Dictionary | Description |
|---|---|
| html.entities.html5 | A dictionary that converts HTML5 named character references 1 to the corresponding Unicode character(s), for example, html5[‘lt;’] == ‘<‘. |
| html.entities.entitydefs | A dictionary that maps XHTML 1.0 entity definitions to ISO Latin-1 replacement text. |
| html.entities.name2codepoint | A dictionary that converts HTML entity names to Unicode code points. |
| html.entities.codepoint2name | A dictionary that associates Unicode code points with HTML entity names. |
Final Thoughts
Now you know the Python HTML module and how to use its functionalities like encoding and decoding HTML code. You can handle HTML with ease using Python.
I hope you find this tutorial useful. If you like this article, please leave a comment and share it with your friends who wish to learn Python topics.
Recent Posts
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules. In this tutorial, let's understand what modular...
While Flask provides the essentials to get a web application up and running, it doesn't force anything upon the developer. This means that many features aren't included in the core framework....
