As a data scientist working with real-world data, you will confront the difficulty of building a machine learning model on unbalanced data at some time in your career. You will need to make wise decisions on several issues, like picking the appropriate measure for assuring enough training for your model in minor classes.
This article will introduce you to the imbalanced-learn module in Python and show you its top two most frequent use cases to assist you in developing an accurate and informative model.
Imbalanced-learn Module in Python
Imbalanced-learn is a Python package used in machine learning to handle imbalanced datasets. The amount of data samples in an unbalanced dataset is not distributed evenly throughout the classes. The class labels in an unbalanced dataset are not equal. One class label has a much bigger number of data samples than the other class label.
For example, suppose you’re forecasting whether a student will pass or fail an exam based on a variety of input characteristics. We have two class names in this example: pass and not pass.
The incorporated approaches are divided into four categories:
- Over-sampling.
- Under-sampling.
- A mix of over- and under-sampling.
- Ensemble learning methods.
Here in this article, we are going to focus on the approach of over-sampling.
Oversampling
Oversampling (sometimes known as upsampling) is the inverse of undersampling. In this case, the class with fewer data is deemed equal to the class with more data. This is accomplished by adding extra data to the class with the fewest samples. As a result, the ratio will be 1:1 and balanced.
Resampling techniques are one of the most effective approaches for dealing with skewed data. The Python imbalanced-learn module provides many resampling algorithms and implementations, including the two most useful techniques: SMOTE and ADASYN.
SMOTE and ADASYN
Synthetic Minority Oversampling Technique (SMOTE) and Adaptive Synthetic (ADASYN) are two oversampling methodologies. These similarly produce few samples, however, ADASYN considers the density of distribution to disperse the data points uniformly.
Prerequisites
You should be aware of the following:
- Python programming fundamentals
- A primer on machine learning
- A basic overview of Pandas
Installation of Imbalanced-Learn
Let’s run the following command to install it:
sudo pip install -U imbalanced-learnThat’s all! Imbalanced-learn has been installed and is ready to use. Let us now load our unbalanced dataset.
SMOTE
Oversampling instances from the minority class, for example, by simply duplicating examples from the minority class, is one technique to overcome this problem. Such an approach provides no more information to the model. Generating synthetic instances would be a better approach.
SMOTE (Synthetic Minority Oversampling Technique), is a popular method for producing synthetic instances for the minority class.
It operates as follows:
- Choosing a representative from the minority group at random.
- Determining the k (usually k=5) closest neighbors of that example.
- Choosing a random sample from among those neighbors.
- A line is drawn between the two examples.
- Constructing a fictitious example by selecting a random point on that line.
You’ll now see how to implement the imbalanced-learn module. To demonstrate, utilize the Credit Card Fraud Detection dataset, which can be found here.
Since this dataset is severely unbalanced, it will provide an excellent demonstration set.
After downloading the dataset, you’ll notice that it includes 28 anonymized features along with time, quantity, and class.
import pandas as pd
data = pd.read_csv("creditcard.csv")
data.head()
Put the features in array X and the labels in array Y.
X = data.drop('Class', axis=1)
y = data['Class']
SMOTE will now be used to oversample the minor class such that the two classes in the dataset are balanced.
from imblearn.over_sampling import SMOTE
oversample = SMOTE()
X_smote, y_smote = oversample.fit_resample(X, y)The classes are now balanced, as can be seen below:
X_smote = pd.DataFrame(X_smote)
y_smote = pd.DataFrame(y_smote)
y_smote.iloc[:, 0].value_counts()Let’s make a train-test split now:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_smote, y_smote, test_size=0.2, random_state=0
)
import numpy as np
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)Then, train and test a basic classifier as shown below:
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf.fit(X_train, y_train)Finally, look at the performance:
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")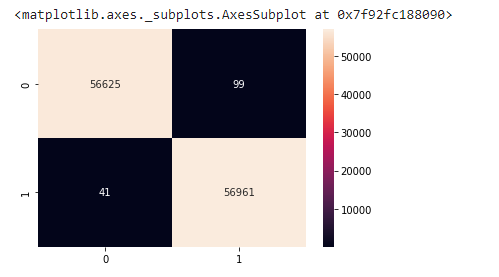
As you can see, using SMOTE ensures that the classifier delivers generally balanced classifications, as opposed to a failed model in which the classifier may categorize all data as belonging to the majority class.
SMOTE enables the generation of samples. However, this approach of over-sampling has no knowledge of the underlying distribution. As a result, some noisy samples may be created, for example, when the different classes cannot be clearly differentiated.
An undersampling approach will be useful to clean the noisy samples. Imbalanced-learn includes two samplers that are ready to use: SMOTETomek and SMOTEENN.
To know more about them, click here.
ADASYN
SMOTE concepts are expanded upon by ADASYN. ADASYN, in particular, picks minority samples S in such a way that “more difficult to categorize” minority samples are more likely to be chosen.
This provides the classifier with additional opportunities to learn difficult cases. The code for ADASYN is identical to that of SMOTE: simply replace the term “SMOTE” with “ADASYN.”
from imblearn.over_sampling import ADASYN
oversample = ADASYN()
X_adasyn, y_adasyn = oversample.fit_resample(X, y)
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = clf.predict(X_test)
cm2 = confusion_matrix(y_test, y_pred.round())
sns.heatmap(cm2, annot=True, fmt=".0f")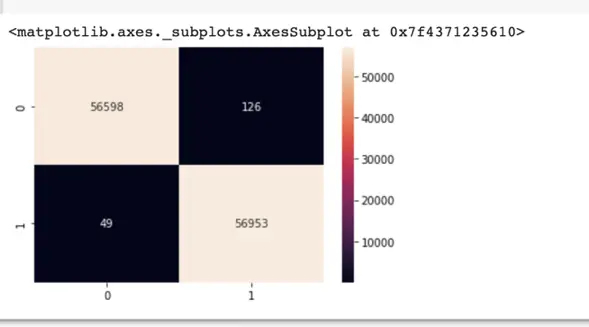
Final Thoughts
We discussed the imbalanced-learn package in this article. We went through the imbalanced-learn module installation procedure and looked at several techniques for dealing with imbalanced datasets.
The ability to confidently approach problems with unbalanced data is a valuable skill for a data scientist. The library imbalanced-learn provides you with the necessary tools.
To deep dive further into this topic, it is recommended to read the well-written official documentation for imbalanced-learn, which is accessible at https://imbalanced-learn.readthedocs.io/en/stable/.
Happy coding!
Recent Posts
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules. In this tutorial, let's understand what modular...
While Flask provides the essentials to get a web application up and running, it doesn't force anything upon the developer. This means that many features aren't included in the core framework....
